kiVide
KI-basierte Videoanalyse für Fußballspiele
![Lorem Ipsum]()
Funktionsweise
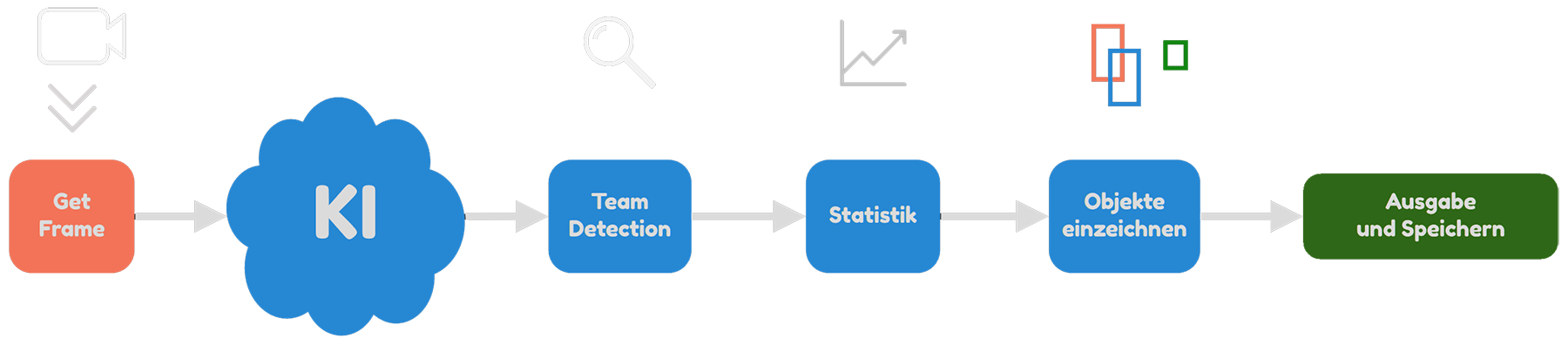
Roadmap
-
Test mit fertigem Modell
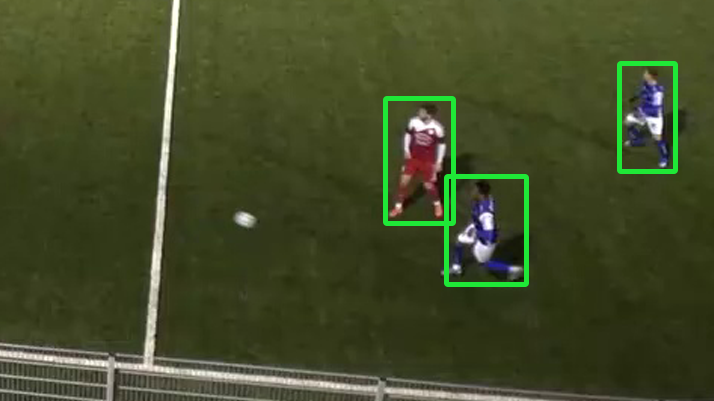
- Für die ersten Tests nutzten wir den frei verfügbaren Coco-Datensatz.
- Spieler konnten wir damit recht gut erkennen, doch die Bälle stellten sich als Problem heraus.
- Es war klar, dass wir ein von Grund auf neues Modell trainieren mussten.
![Lorem Ipsum]()
-
Trainingsdaten annotieren
- Aus den aufgezeichneten Videos wurden einzelne Frames ausgewählt.
- Darauf haben wir alle Spieler und Bälle von Hand eingezeichnet.
- Mit unseren 1200 Ausschnitten wurde unser KI-Modell trainiert.
![Lorem Ipsum]()
-
Automatische Annotation der Trainingsdaten
- Das händische Annotieren war äußerst zeitaufwändig, also suchten wir schnellere Wege zum Ziel.
- Wir probierten Tools zur automatisierten Annotation, von denen keines zufriedenstellende Ergebnisse lieferte.
-
Eigenes Modell trainieren
- Unser KI-Modell basiert auf dem weit verbreiteten Darknet-Framework.
- Das Trainieren von KI-Modellen erfordert extreme Rechenleistung. Wir benutzten Google Colab, um unsere Modelle in der Cloud zu trainieren.
- Ein Trainingsdurchlauf dauerte etwa 12 Stunden.
- Insgesamt trainierten wir 7 Modelle.
-
Trainingsdaten augmentieren und synthetisieren
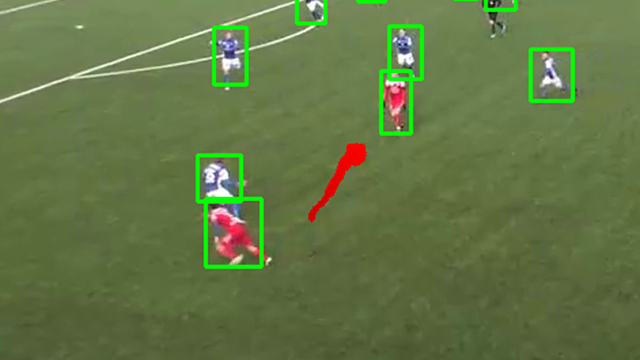
- Das Finden des Balles war unsere größte Herausforderung, da er extrem klein ist.
- Wir setzten Bildaugmentierung ein, um die Erkennungsrate der KI zu steigern.
- Große Fortschritte brachte erst die Synthese von Trainingsdaten. Das steigerte die Erkennungsgenauigkeit des Balles am Ende auf 37 %, die der Spieler auf 61 %.
![Lorem Ipsum]()
-
Tracking
- Neben Erkennung durch KI untersuchten wir auch den Einsatz von Object Tracking.
- Ein einzelner Fußball lässt sich damit durchaus gut verfolgen.
- Probleme kommen, wenn Spieler in Ballnähe sind - in 9 von 10 Fällen verfolgt der Tracker lieber einen Schuh als den Ball.
- Aufgrund der Unzuverlässigkeit des Trackings nahmen wir diese Technologie nicht in unser System auf.
![Lorem Ipsum]()
-
Bildvorverarbeitung
- Um die KI zu beschleunigen, überlegten wir uns Wege, wie wir irrelevante Informationen aus dem Video beseitigen konnten.
- Wir erreichten eine gute Kantendetektion mit OpenCV, mit der wir ein Spielfeld aus dem laufenden Video ausschneiden können.
- Am Ende war die Performance die gleiche, also verfolgten wir die Idee nicht weiter.
![Lorem Ipsum]()
-
System auf GPU portieren
- Mittels CUDA lassen wir unsere KI auf einer dedizierten Grafikkarte laufen.
- Der Leistungsunterschied im Vergleich mit dem Rechnen auf der CPU ist dabei enorm.
- Unser Testsystem (Ryzen 7 5800x & Nvidia GTX1070 TI mit 8 GB VRAM) erreicht 10 FPS beim Rechnen der KI.
-
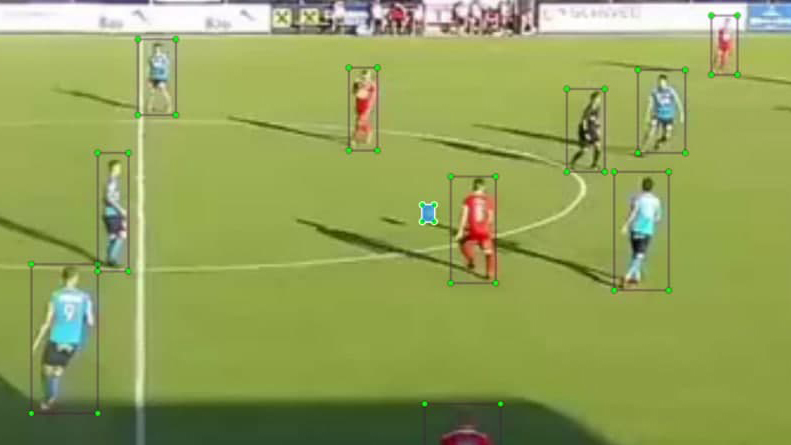
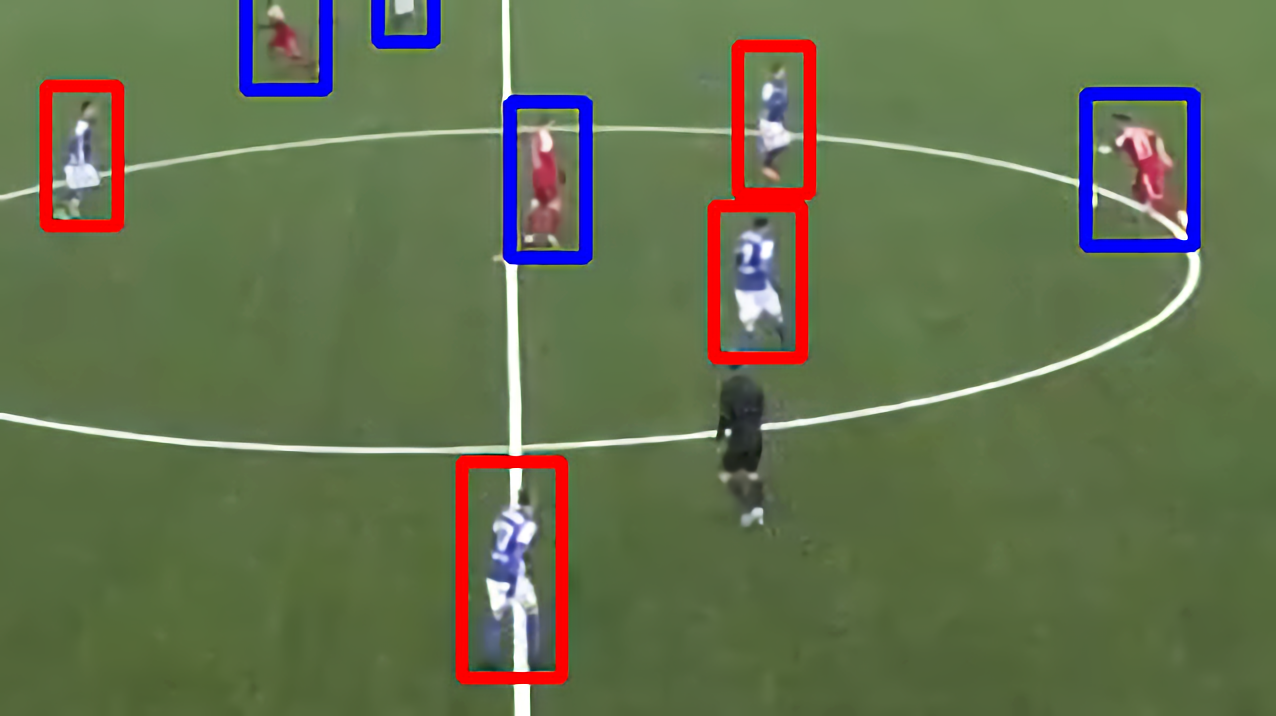
Teamerkennung
- Um Statistiken aus den erkannten Spielern abzuleiten, müssen wir wissen, zu welchem Team sie gehören.
- Wir kombinieren Farberkennung mittels Durchschnittswerten mit k-means-Clustering, um die Spieler anhand der Trikotfarben in zwei Teams einzuteilen.
![Lorem Ipsum]()
-
Statistiken
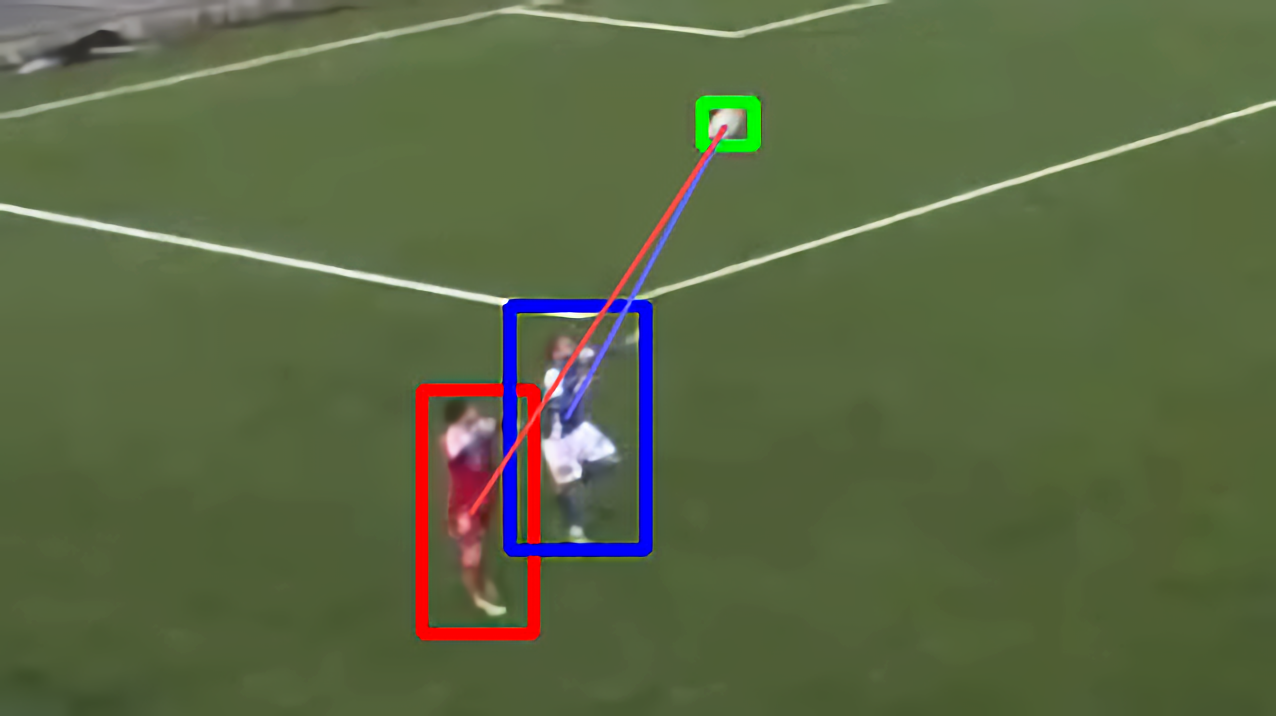
- Die verlässlichste Statistik, die wir aus unseren Daten ziehen können, ist der Ballbesitz.
- Anhand der euklidischen Distanz zum Ball können wir den nähesten Spieler erfassen.
- Je nach Teamfarbe des nähesten Spielers wird Bild für Bild der aktuelle Ballbesitz berechnet.
![Lorem Ipsum]()
-
GUI
- Eine grafische Oberfläche verbindet alle Komponenten unseres KI-Systems.
- Die GUI erlaubt das Ein- und Ausschalten der einzelnen Arbeitsschritte sowie eine leicht verständliche Darstellung der Ballbesitzstatistik.
![Lorem Ipsum]()



Team

Florian Berghuber

Lucas Drack

Philip Ecker

Manuel Kugler

Markus Neuwirt
